Notes - Practical Event-Driven Microservices Architectures
Encrytion & GDPR
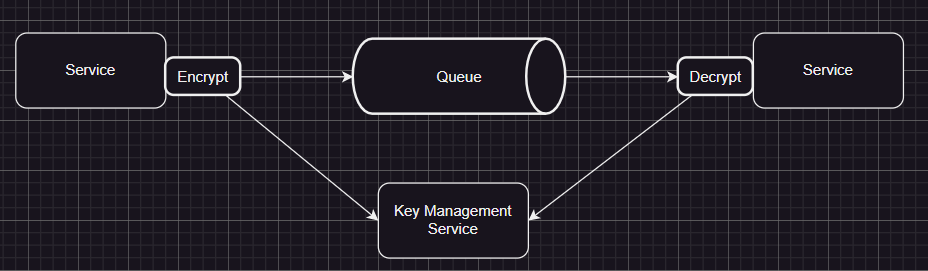
If you are keeping user information, and you need to remove it for legal reasons, it might be harder to do if you’re using event-sourcing. In that case, you can use a key management service to encrypt data, and just remove the key from there when you want it to be removed. So when you don’t have the key, the data will be unaccesible anyway.
Definitions
- Command: It’s an order to service to do something. Typically targeting only a single service.
- Event: Informing that something happened. Better to be used as partial.
- Document: Similar to events, but does not have domain value. It just information about aggregate. In case of documents, you can alsu use something like compacted topics in Kafka, which just keeps the last version of the data.
- Query: Receive information, mostly through http/grpc requests.
Patterns
- Send/Receive: One-to-one commands
- Publish/Subscribe: Mostly for events, multiple services or multiple instances of the same service can subscribe to the same queue.
- Request/Response: Might be used for event-driven systems as well. For instance, UI sends a command and receives an event some time later, through with same identity value.
CQRS
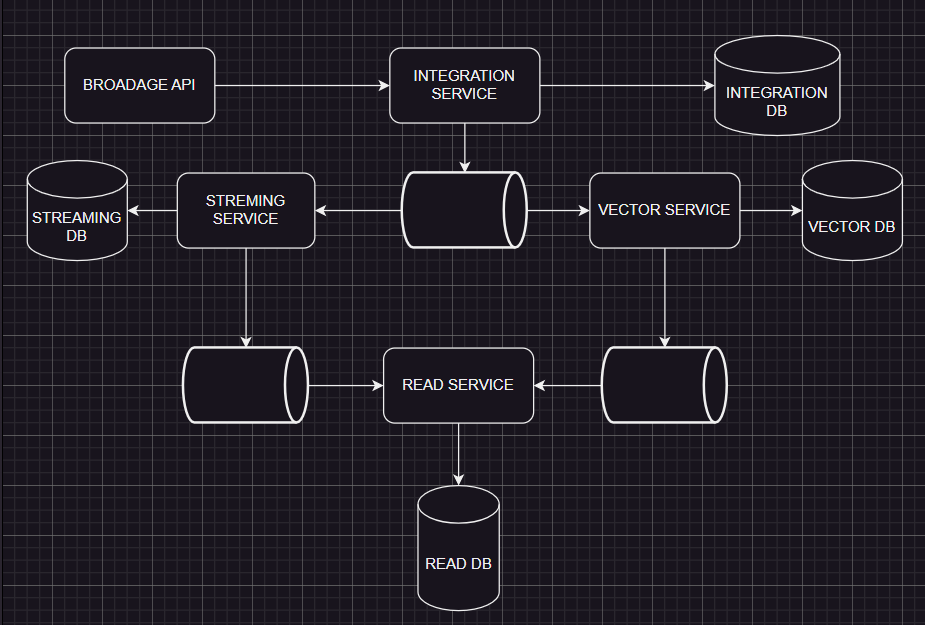
Well, it’s simply just seperating reads and writes, eventual consistency is natural result of this pattern. There are alternative solutions if it’s important but I won’t include here. The image is one of my side projects as an example, as you can see the read model is only for reads.
Concurrency
-
Pessimistic: It’s like asking permission before using a resource. You can access to resource only after getting the lock. You can use Redis for distributed locking for example. The problem with it is, locking is an expensive operation. You should use it only when there is a high chance of conflict.
-
Optimistic: It’s like apologizing if you see a conflict. You chech if anything changed before persistance, if yes you can retry or fail. Retries are expensive, so use it when there is a low chance of conflict. You can use event versioning or timestamps for this.
Out-of-order events
Make sure events will be in the same queue, and broker will not create out-of-order problem. In the book, there is a Kafka example, us,ng the same routinig key(product id), they go to the same partition. And from a partition only one service instance can read. So from broker’s part, there won’t be a problem. However, since the service is a multi-threaded app, there can be out-of-order event problem in the service as well. The book suggests to make sure same routuing key events will be used by the same threads. In my opinion, actor frameworks such as Microsoft Orleans can be a good solution for this case.
Message Delivery Semantics
When the service is communicating with the broker, there can be some issues. Such as event has been sent but broker couldn’t send confirmation due to network problems. Or consumer read the event but couldn’t sned confirmation due to problems.
- at-most-once: No message duplication, but some messages may be lost. Not good for business-critical applications.
- at-least-once: Guaranteed delivery of messages, but there can be duplicated events. This one is the best overall option, but make sure the consumers are idempotent.
- exactly-once: Hard to implement, performance penalty and not every brokers have this feature.
Outbox Pattern
Our event stream should be the source of truth, not the database. We should first publish the event then persist it in the database. To provide data consistency against possible problems in our services, we can use outbox pattern.
- Save the data and event to the tables.
- Read the event from database, you can use CDC, or polling the database, or directly during the operation.
- Publish the event to the broker.
- Delete the event from the database.
You can use transactions to wrap these actions. However, it doesn’t solve everything. What if transaction is rolled back but we published the event? What if transaction is committed but publishing event failed?
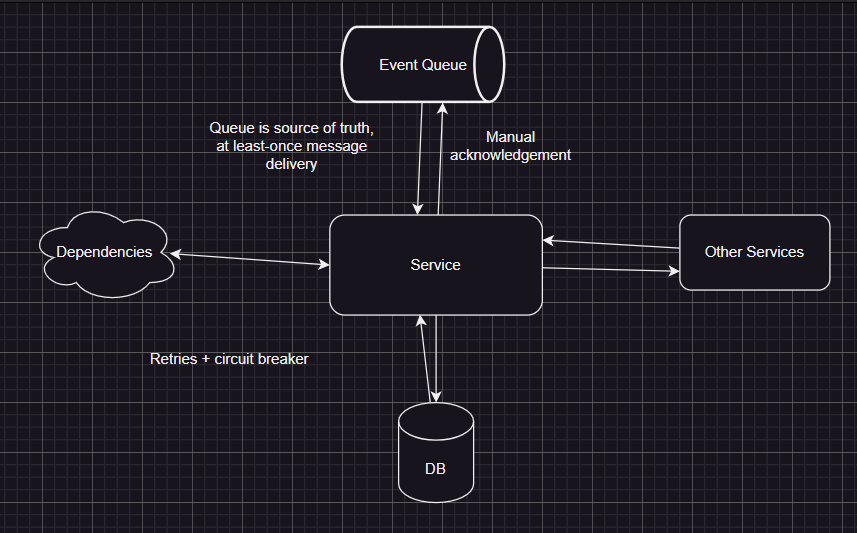
Confirmation must be done after processing the event
What if the service consumes the event, but while processing there is a failure? You already consumed. So you should do manual confirmation, and only confirm after you processed. What if you processed the event, but during confirmation a network error happened. You can consume it again, like it’s mentioned before, your services must be idempotent.
Retries and Circuit Breaker
Retrying can be a good policy to solve temporary errors. Increment retry time after every attempt, if a critical component fails circuit breaker might be a good option; if requests are failing for a spesific number of times, your service stops consuming events aka opening circuit, then after some predefined time if requests are successful your service starts consuming events once again aka closing circuit.
Avoid
Generalized event named
Events need to have domain value. So for instance, instead of OrderChanged, OrderAddressChanged should be used. Be concise as possible.
Synchronous requests
If possible, do not rely on other services like Service B in this picture. Otherwise, you’d end up having distrubuted monolith. If Service A fails here, Service B will fail as well, also when they scale, they need to be scaled together.
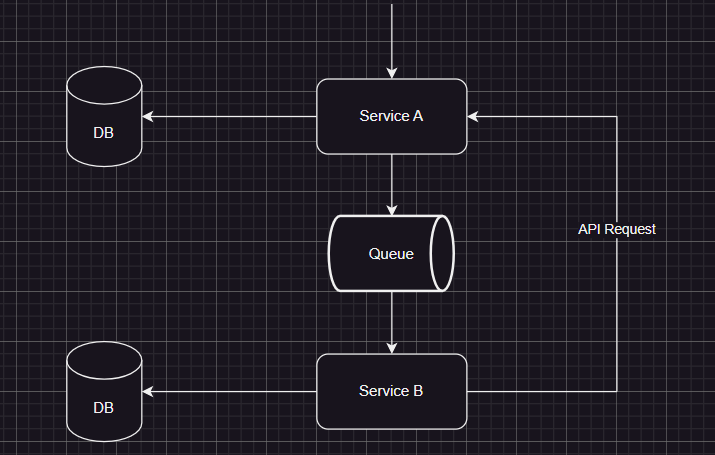
The events should have enough information to not to need additional request if possible. One alternative to changing event’s content is using Bee events which means, Service B will keep the relevant information in its database, so it won’t need to go to Service B. Just like bees fly from flower to flower and spreads their pollens.
Schema Evolution
-
The first option is, add a new field to the event, keep the old one. When all the consumers adapt and start using new field, you can remove the old one. Good for small changes.
-
Second option is, have two different queues, one with the previous schema, one with the new one. After every consumer adapt to use new one, you may stop publishing events to old one. Good for big changes.
Testing
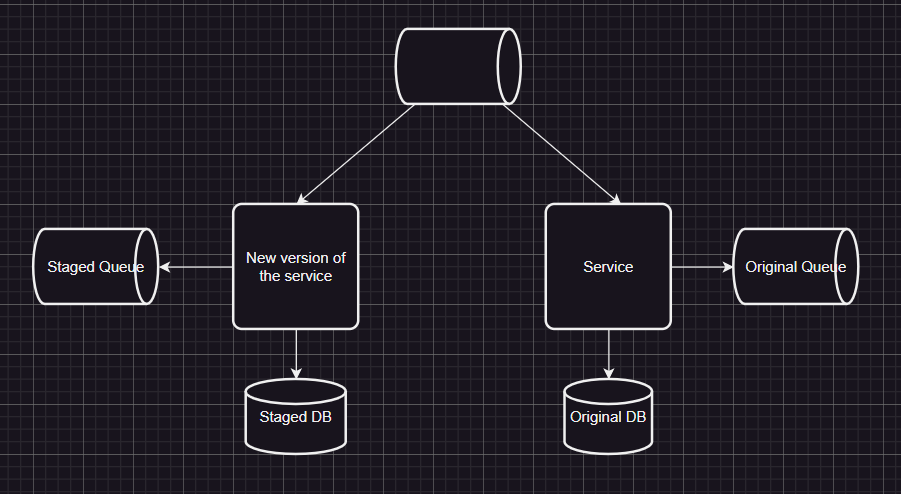
For testing, the book argues that end-to-end tests don’t fit to event driven systems, if the system is complex enough. It also suggest testing in prod, for example deploy the new version of your service next to old one, it’s called shadowing. Since the new service will work with the real data, it’ll be a more correct test. We can also include staged queue and database as well.